Why the pound is down: a crash course in machine learning
1203 words | ~6 min
You might have seen in today's news that the trading value of the pound fell by 6% overnight, apparently triggered by automated currency trading algorithms. Here's how that looked on a chart of sterling's value against the dollar:
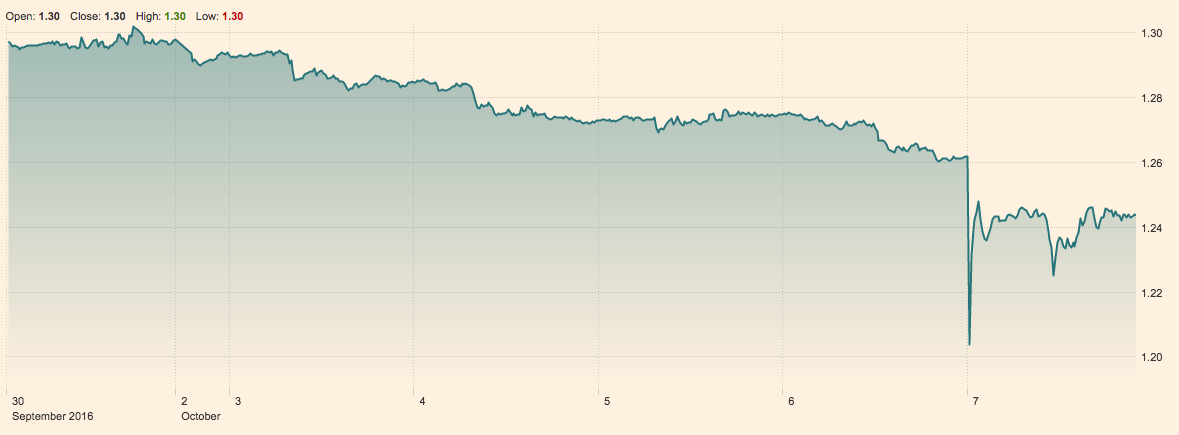 (Source: FT.com)
(Source: FT.com)
It's a fascinating read - we live in a world where decisions made by computers without any human intervention can have this sort of impact. And since 'machine learning' of this kind is a hot topic in marketing right now, and powers a lot of programmatic buying, today's news is a good excuse to think about the basics of how machines learn.
So, here's a a quick guide to how machine learning works, and why the pound in your pocket is worth a bit less than it was when you went to bed (thanks, algorithms).
Anomaly detection: expecting the unexpected
Machine learning is a branch of computer science and statistics, that looks for patterns in data and makes decisions based on what it finds. In financial trading, and in media buying, we need to find abnormalities quickly: a stock that is about to jump in price, a level of sharing around a social post that means it is going viral, or a level of traffic to your ecommerce portal that means you need to start adding more computing power to stop it crashing.
For example, these are Google searches for Volkswagen in the UK over the past five years. See if you can spot when the emission scandal happened.
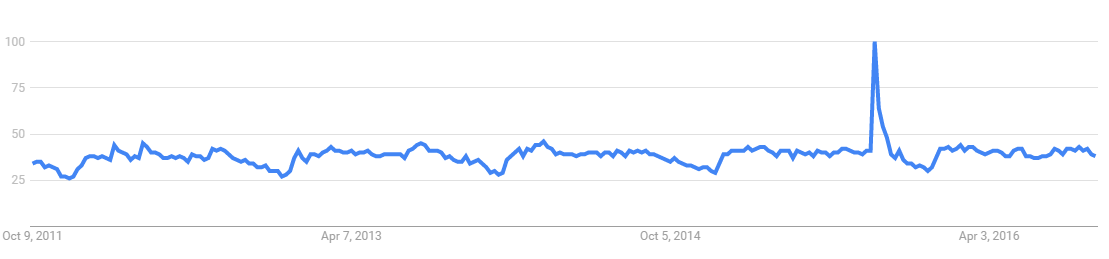
If you wanted to monitor this automatically, you'd use an anomaly detection algorithm. If you've ever used a TV attribution tool, you've seen anomaly detection at work, picking up the jumps in site traffic that are attributable to TV spots.
Anomaly detectors are used to set triggers - rules that say things like If the value of a currency falls by X amount in Y minutes, we think this is abnormal, so start selling it. This is what seems to have happened overnight to the pound. One over-sensitive algorithm starts selling sterling, which drives down its value further, so other slightly less sensitive algorithms notice and start selling, which drives down the price further, and so on...
Conditional probability: playing the odds
Most decision-making, especially at speed, isn't based on complete certainty. Algorithms need to be able to make decisions based on a level of confidence rather than total knowledge.
For example, is this a duck or a rabbit?

At this point you might say 'I don't know' - i.e. you assign 50:50 odds.
How about now?

You take in new information to make a decision - if it quacks out of that end, it's a duck. (Probably.)
This is conditional probability - updating your confidence based on a new information in context. 'This is either a rabbit or a duck', becomes 'this is a duck, given that it quacks'. We use conditional probability in digital attribution ('what is the likelihood of converting if you have seen this ad, vs if you haven't?') and we use it in audience targeting for programmatic buying: given that I've seen you on a whole load of wedding planning sites, what is the likelihood that you're planning a wedding?
Again, conditional probability can go wrong if we're too strict or not strict enough with our conditions. If I decide you're planning a wedding because I've seen you on one vaguely wedding-related site, I'm probably going to be wrong a lot of the time (known as a high false positive match rate). If I insist that I have to see you on 100 wedding planning sites before I target you as a wedding planner, I'm going to miss lots of people who really are planning weddings (a low true positive match rate).
Currency trading algorithms use conditional probability: given that the value of the pound is down X% in Y minutes, how likely is it that the pound is going to fall even lower? An over-sensitive algorithm, with too high a false positive rate, can start selling the pound when there's nothing to worry about.
Inference: how machines learn, and how we use brands
Anomaly detection and conditional probability are used together to help machines learn and classify, known as inference because computers are inferring information from data.
For example, a few years ago Google trained an algorithm to recognise whether YouTube videos contained cats. It did this by analysing the frame-by-frame image data from thousands of videos that did contain cats.

But it also trained the algorithm on lots of videos that weren't cats. That's because the algorithm is a classifier, designed to assign items to different categories. The Google classifier was designed to answer the question: does this image data look more like the videos of cats I've seen, or more like the videos of not-cats?
Good inference requires these training sets of data so that. A badly-trained classifier will assign too many things to the category it knows best, assuming that everything with a big face and whiskers is a cat.

We use classifiers in audience targeting and programmatic buying, to assign online users to target audience groups. For example, in Turbine (the Xaxis data platform) each user profile might have thousands of different data points attached to it. A classifier will look at all of these and, based on what it's seen before, make a decision about whether a user is old or young, rich or poor, male or female... So inference and classification are vital for turning all those data points into audiences that we can select and target.
But we are also classifiers ourselves - our brains are lazy and designed to make decisions at speed. So when we go into the supermarket we look for cues that the thing we're picking up is our normal trusted brand of butter, bathroom cleaner or washing-up liquid. Retailers like Aldi hijack our inbuilt classification mechanisms to prompt us to choose their own brands:

From metrics to models
There's so much data available to us now - as marketers, as well as stock traders - that we can't look at each data point individually before making decisions. We have to do get used to using techniques like anomaly detection, conditional probability and classification to guide us and show us what is probably the right thing to do, to optimise our media or our creative. Machine learning can help us do this faster and using larger volumes of data. At Maxus we call this moving from metrics to models and it's one of the things we can help clients do to be more effective in their marketing. As we've seen today on the currency market, though, it can be scary and it can have unexpected consequences if not done properly.
# Alex Steer (08/10/2016)